Clinical Decision Support System for COVID-19 patients management
Everybody has head about COVID
The first case of COVID-19 was detected in Wuhan, China, on December 31st, 2019. Soon after, the WHO has characterized this viral disease as a global pandemic. Many governments have imposed a lockdown to protect the NHS from being overwhelmed and limit the spread of the disease. Since then, the COVID-19 has seriously impacted businesses and the economy. It also has been had serious implications for people’s livelihoods and health. For example, my 6 months of industrial placement as a Data Scientist in Airbus has been canceled.
The Goal
EPIC IMPOC is a clinical decision support system used in the NHS to improve the management of infectious diseases by facilitating data collection, infection diagnostics, and antimicrobial therapy advice at the point of care.
In the midst of the SARS-CoV-2 outbreak, we have implemented a new module for EPIC IMPOC (Enhanced, Personalized, and Integrated Care for Infection Management at the Point of Care), specifically to provide aid to clinicians to diagnose COVID-19 patients and treat them by retrieving similar cases.
The Final Solution
This module is a new component of EPIC IMPOC that focuses specifically on integrating current medical knowledge of COVID-19 and patient data with an inference engine to predict the likelihood of infection.
Additionally, it includes a patient retrieval system that is packaged in a desktop-friendly panel for clinicians within EPIC IMPOC to identify patients with similar severity levels, symptoms, and medical histories in the UK.
This EPIC IMPOC module is one of the first planned to undergo clinical trials in the NHS, starting in early July 2020. This solution will be a crucial part of the Imperial College Healthcare NHS Trust’s COVID-19 response to the second wave in the pandemic. The Trust’s five hospitals currently treat more than 1.125 million patients and employ 11,800 people annually.
Technical Overview and Learning outcomes
Data Preprocessing and Pipeline
During this project, I have preprocessed the data using Pandas library and selected the most important features using Random Forests. I have also built a data pipeline that includes: data filtering, data imputation, and data scaling that maximizes the Probabilistic Inference Module and the Case Base Reasoning system performances.
Probabilistic Inference Module
I have also worked on the Probabilistic Inference module estimates the probability of COVID-19 infection in a patient based on key pathology data. I have evaluated different machine learning algorithms using mainly Scikit Learn library, and the following algorithms were selected: LightGBM, Random Forest Classifier, and Decision Tree Classifier.
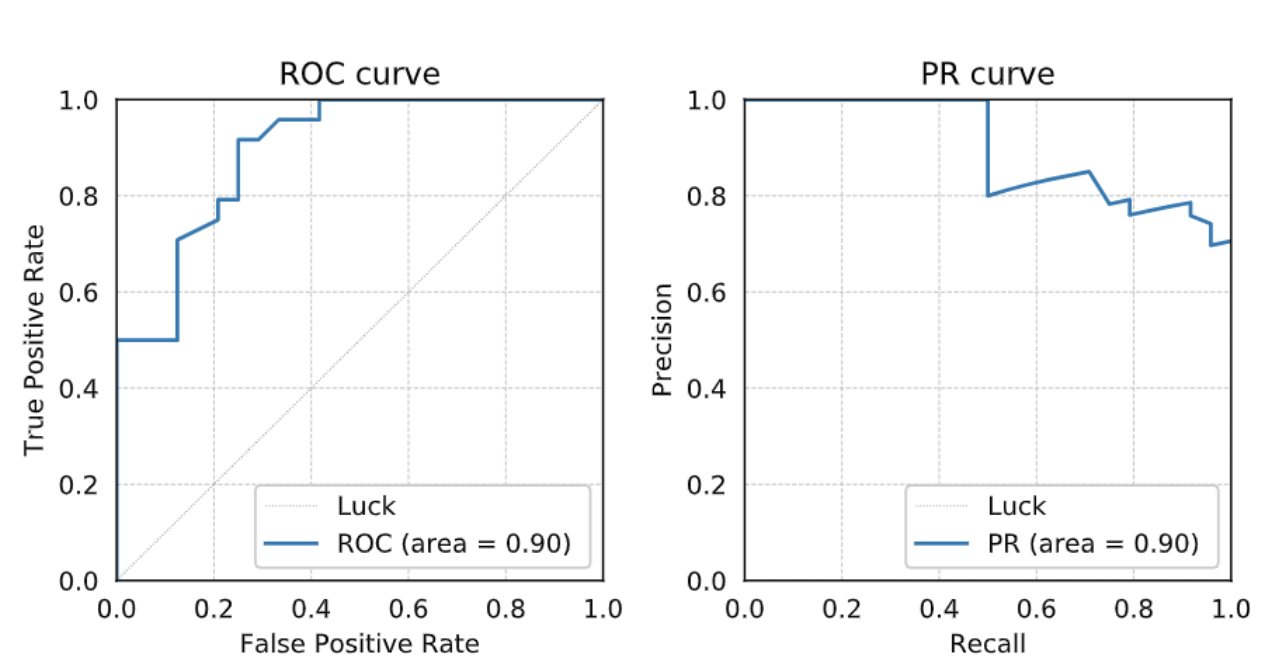
LightGBM Performance in Predicting SARS-COV-2 Infection Based on Patients' Blood Tests
Case Base Reasoning System
Finally, I have implemented the Case Base Reasoning system that retrieves similar patients and provide them to the clinicians to support them with treatment prescription using, on the one hand, the pathology profile, and on the other hand, the vital signs, symptoms, radiology results and medical history of the patient.
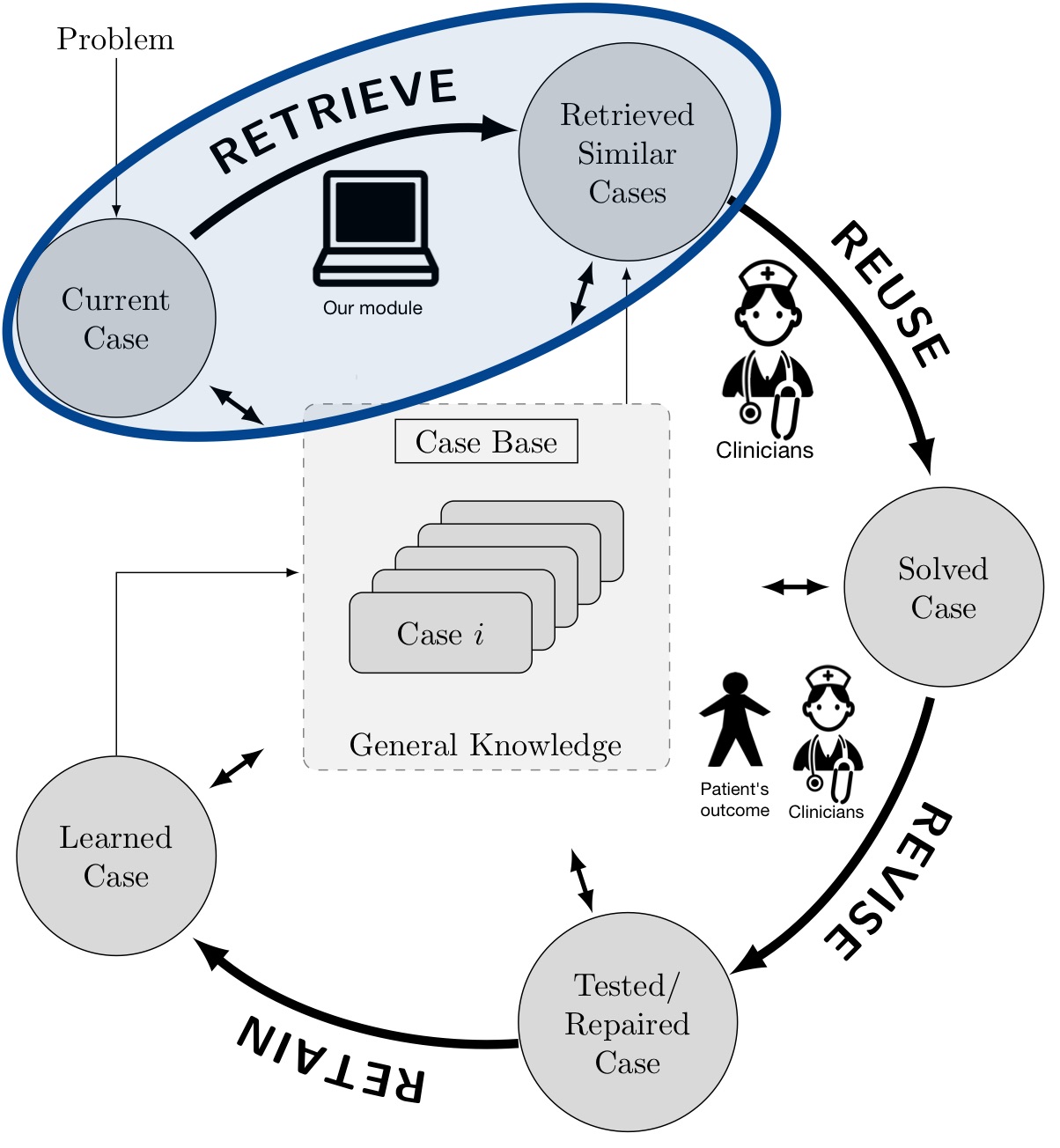
The CBR cycle - the 4 phases of the CBR cycle according to Aamodt and Plaza
This has been done by computing the weighted distance between a given patient and the remainder of cases and selecting the most similar cases. The system performance was evaluated using the patient outcome to verify and investigate patient similarities.
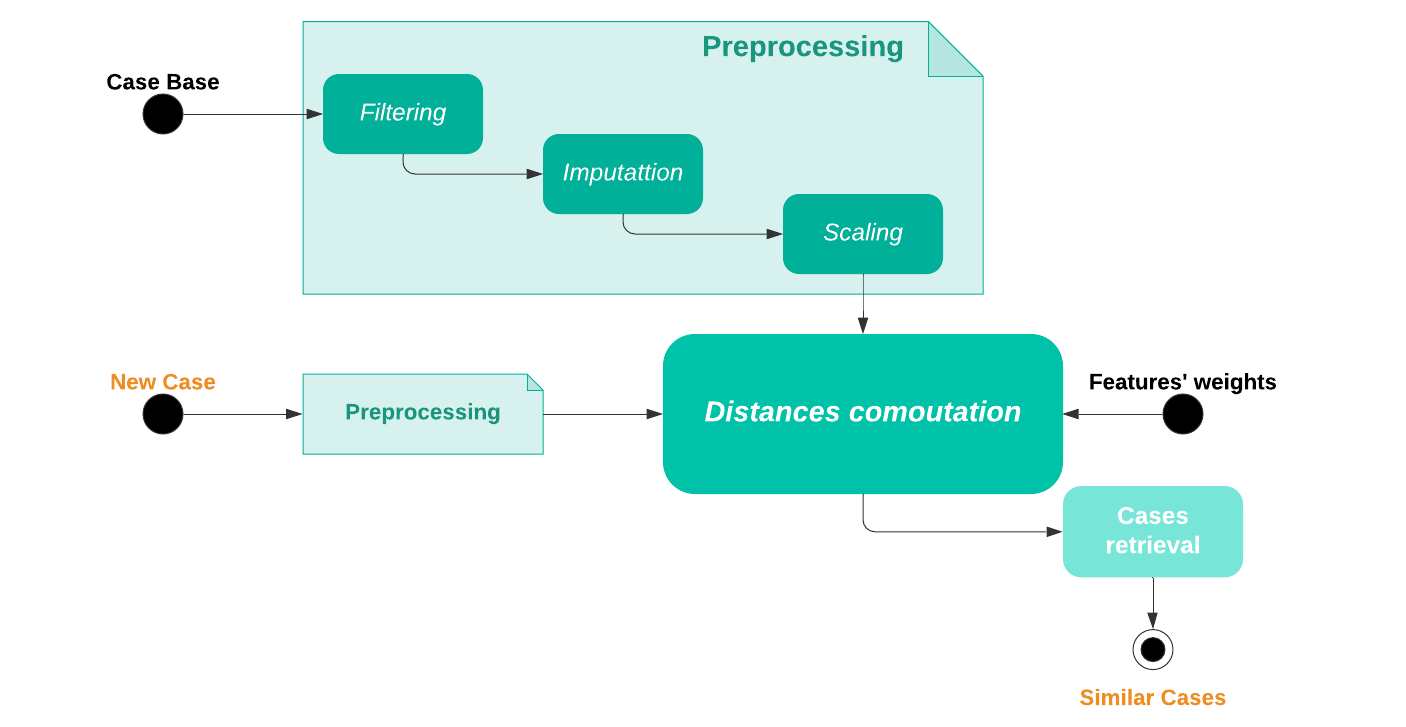
Workflow of the Supervised CBR
To evaluate the quality of the retrieved patients, a simple voting system was used to predict the patients' outcomes. The percentage of retrieved patients that have been admitted to the ICU/died was compared to a predefined threshold. In fact, after observing that the classes are highly imbalanced, the threshold has been lowered to maximize performance.
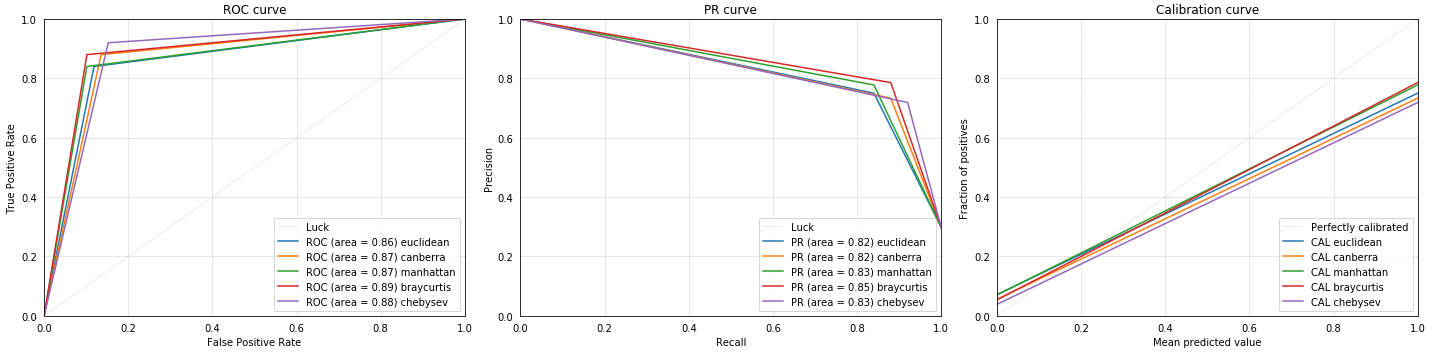
Comparaison of the CBR Performance in Death prediction for Different Distance Metrics
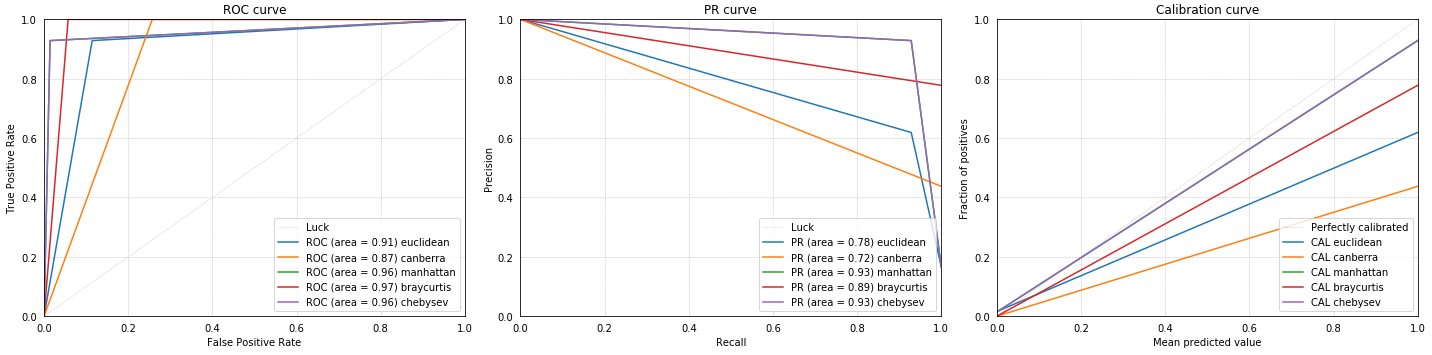
Comparaison of the CBR Performance in ICU Prediction for Different Distance Metrics
Finally, I have worked with the “Back-end Django Application Team” in order to integrate the machine learning models and the data pipeline with the Django Application.